We present an efficient and robust pipeline for multi-class NSFW image classification. The method combines a modernized EfficientNet-inspired backbone with configurable attention mechanisms, flexible normalization, and a compact multi-layer classifier. A two-stage procedure is employed: (1) a constrained architecture and hyperparameter search on a balanced subset of approximately fifty thousand images to identify high-potential configurations; and (2) full-scale training of the selected model for final performance. The system emphasizes macro-averaged metrics to cope with class imbalance and provides a practical balance between accuracy and computational efficiency.
Automated NSFW image classification supports safety filtering and content moderation. However, visual signals can be subtle and datasets often exhibit class imbalance and domain shift. We aim to design a model that is accurate, efficient, and robust under such conditions. Building on the strengths of mobile inverted bottleneck architectures, our approach augments the backbone with attention and normalization choices that improve expressiveness without incurring prohibitive computational cost. We further integrate a structured hyperparameter search to systematically explore model and training configurations within a limited compute budget.
Early CNNs for image classification have evolved toward efficient mobile architectures and multi-branch attention modules. EfficientNet introduced compound scaling principles that inspired many subsequent designs. Channel and spatial attention mechanisms such as Squeeze-and-Excitation (SE), Efficient Channel Attention (ECA), and CBAM have shown improvements across diverse tasks. For optimization under class imbalance, focal and Dice losses are widely used. Our work combines these advances in a single, configurable pipeline tailored to NSFW classification.
The backbone follows the mobile inverted bottleneck (MBConv) paradigm with depthwise separable convolutions and residual connections where feasible. Each block includes:
The network is organized into stages, each defined by the number of blocks, output channels, stride, and expansion ratio. A final projection to a high-dimensional representation is followed by global pooling and a lightweight classifier composed of one or two hidden layers with dropout and non-linear activations. This design aims to capture fine-grained cues necessary for NSFW distinctions while remaining compute-friendly.
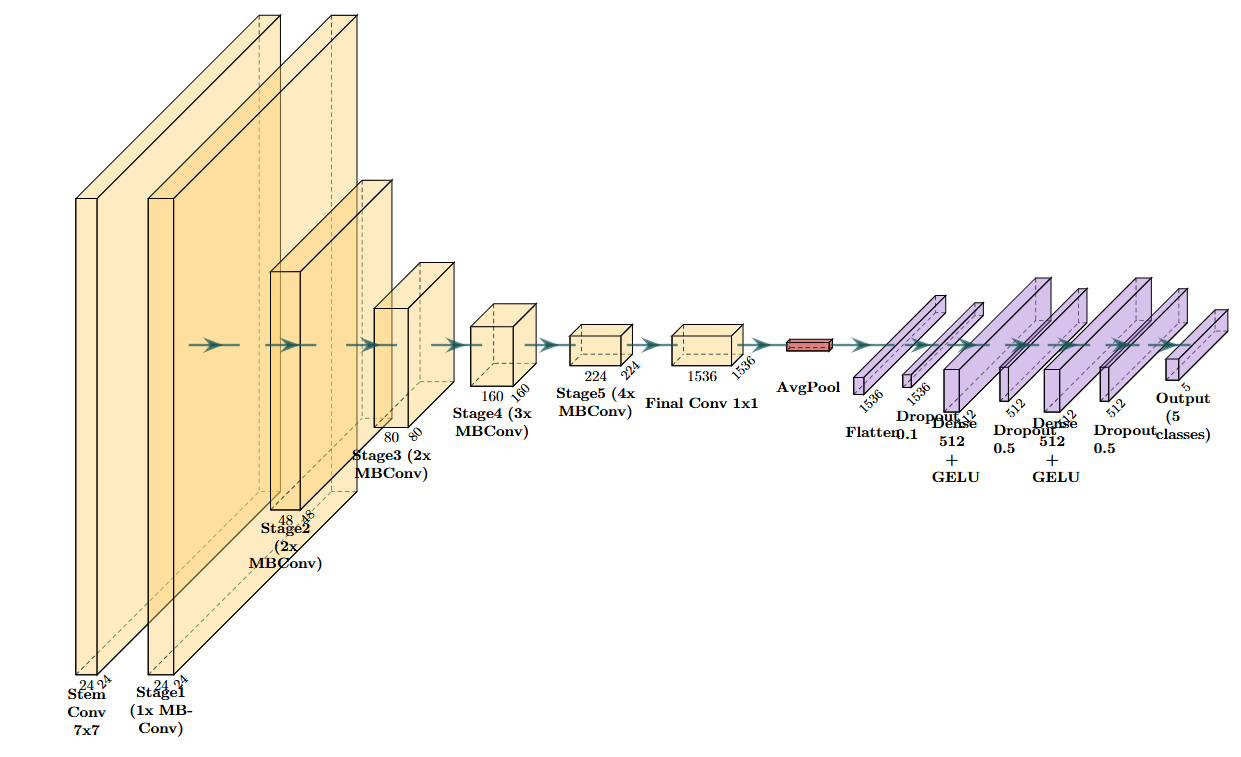
Figure 1 provides a high-level schematic of the proposed model, showing the stem, successive MBConv stages with increasing channels and downsampling, the final 1×1 projection, global average pooling, and the compact multi-layer classifier.
We consider channel-centric attention (SE, ECA), a combined channel–spatial approach (CBAM), and the option of disabling attention for ablations. Normalization choices include batch normalization and a layer-normalization-like variant implemented via grouped normalization. Activation functions are drawn from GELU, SiLU (Swish), and ReLU. Stochastic depth (drop-connect) is applied with a linearly increasing rate across depth to regularize training.
The classifier maps the pooled representation through a compact multi-layer perceptron with dropout. Non-linearities use GELU by default due to its favorable smoothness. The final linear layer outputs logits for the five-class taxonomy.
The architecture descends from EfficientNet-B2 through the use of MBConv blocks, depthwise separable convolutions, and compound scaling principles that relate depth, width, and resolution. In contrast to the original formulation, the present design incorporates modernization strategies inspired by the ConvNeXt family (A ConvNet for the 2020s), including:
While ConvNeXt reimagines residual CNNs, the current approach adapts several of its modernization heuristics to the inverted-bottleneck regime: we retain the expansion–depthwise–projection structure that is characteristic of EfficientNet-style models but adjust kernel sizes, activation functions, and regularization (drop-connect) to strengthen expressiveness and generalization. The classifier head is made slightly deeper (one to two hidden layers with dropout) to improve class separability for nuanced NSFW categories.
Each inverted bottleneck block maps an input tensor \(\mathbf{X} \in \mathbb{R}^{H \times W \times C_{in}}\) to \(\mathbf{Y} \in \mathbb{R}^{H' \times W' \times C_{out}}\) via three stages:
Compared to a standard dense convolution with cost \(\mathcal{O}(H'W' \cdot k^2 \cdot C_{in} \cdot C_{out})\), the factorized depthwise–pointwise design reduces spatial mixing cost and amortizes channel mixing through efficient \(1\times1\) convolutions. Residual connections are used when \((s=1)\) and \((C_{in}=C_{out})\), yielding \(\mathbf{Y} = \mathbf{X} + \mathcal{F}(\mathbf{X})\) where \(\mathcal{F}\) denotes the expansion–depthwise–projection stack and any attention and normalization.
We consider lightweight attention to refine feature reweighting without incurring significant overhead:
Normalization affects optimization stability and generalization. Batch normalization (BN) is effective when batch statistics are reliable; layer-normalization-like behavior can be approximated via GroupNorm with one group (GN(1)) for small-batch regimes. Smooth activations (GELU, SiLU) exhibit better optimization characteristics in deep, narrow networks than hard-threshold ReLU. We adopt post-activation placements within sub-layers and maintain consistency across the network to stabilize gradient flow.
The network comprises a stem followed by multiple stages. Stage \(i\) is parameterized by \((n_i, C_i, s_i, e_i, k_i)\) denoting the number of blocks, output channels, stride, expansion ratio, and kernel size. Width is scaled via a width multiplier \(w\), setting channels approximately to \(\lfloor w \cdot C_i \rceil\) while preserving topological layout. Inspired by EfficientNet’s compound scaling, we emphasize width scaling in this work to control capacity with minimal architectural overhead; resolution is chosen from a small discrete set to balance accuracy and compute.
Stochastic depth combats co-adaptation by randomly dropping residual paths during training. For block index \(\ell\) among \(L\) total blocks, a survival probability \(p_{\ell} = 1 - \mathrm{drop}\_\mathrm{max} \cdot \frac{\ell}{L-1}\) is used. During training, the residual addition becomes \(\mathbf{Y} = \mathbf{X} + \mathbf{M}_{\ell} \odot \mathcal{F}(\mathbf{X})\) where \(\mathbf{M}_{\ell} \sim \mathrm{Bernoulli}(p_{\ell})\) and \(\odot\) denotes elementwise multiplication; at inference, the expected residual is recovered implicitly. This yields deeper effective ensembles without increasing inference cost.
Global average pooling produces a compact representation that feeds a shallow multi-layer perceptron with dropout and smooth activations. The head’s depth (one–two hidden layers) improves class separability for nuanced categories while keeping parameter count modest. Label smoothing \(\epsilon\) can be applied to mitigate overconfidence, with smoothed targets \(\tilde{\mathbf{y}} = (1-\epsilon)\,\mathbf{y} + \frac{\epsilon}{C}\mathbf{1}\), improving calibration under class imbalance.
Larger depthwise kernels increase the effective receptive field at minimal parameter cost, approximating long-range spatial interactions akin to attention, but without quadratic complexity. Channel-focused attention further refines discriminative cues. The combination of GELU activations, consistent normalization, and stochastic depth yields stable optimization and improved generalization. The overall design targets a Pareto-efficient point in the accuracy–latency–memory trade-off space suitable for practical deployment.
Relative to EfficientNet-B2, the proposed design maintains the inverted-bottleneck topology and scaling intuition but modernizes spatial mixing (larger depthwise kernels), attention (lightweight channel gating), and non-linearities (GELU). Relative to ConvNeXt, which reforms ResNet-style blocks, our approach transfers ConvNeXt heuristics to the MBConv regime, preserving depthwise separability and inverted bottlenecks that are well-suited to efficient mobile-style networks.
We use a five-class NSFW taxonomy comprising categories such as Drawing, Hentai, Neutral, Porn, and Sexy. The dataset is split into training, validation, and test partitions. To reduce the impact of corrupted samples, truncated image loading is enabled and data validation routines are used to identify problematic files.
Training-time augmentation includes random resized cropping, mild rotations, horizontal flipping, brightness/contrast jitter, and random erasing, followed by per-channel normalization. Validation and test-time preprocessing consist of resizing, centered cropping, and normalization. These augmentations improve robustness and reduce overfitting without significantly altering scene semantics.
A two-stage process is employed. First, a balanced subset totaling roughly fifty thousand images is sampled to bound the cost of exploration. On this subset, a Bayesian hyperparameter sweep searches over architecture (e.g., kernel size, attention type, normalization scheme, expansion ratio, final channel count), classifier head depth and width, regularization (dropout and drop-connect), and training parameters (batch size, image resolution, optimizer, learning rates for backbone and head, weight decay, scheduler, and loss settings).
To avoid unstable or obviously suboptimal configurations, constraints are enforced during the search. For example, incompatible choices of normalization and activation are disallowed; expansion ratios are restricted to a practical range; and certain optimizer–normalization combinations are filtered. Mixed precision and gradient clipping are used to stabilize training in the exploratory stage.
Macro-averaged F1 on the validation subset serves as the primary selection criterion, reflecting balanced performance across classes. Accuracy and, when feasible, ROC-AUC (one-vs-rest) complement the analysis. The best configuration from the sweep is then advanced to full training.
The following table summarizes the parameters explored during the sweep, their candidate values or ranges, and the rationale for inclusion.
| Parameter | Type | Values / Range | Rationale |
|---|---|---|---|
| Batch size | Training | [16, 32, 48] | Throughput vs. stability trade-off |
| Image size | Training | [224, 260] | Accuracy vs. compute; maintains efficiency |
| Kernel size (depthwise) | Architecture | [3, 5, 7] | Receptive field; larger kernels inspired by ConvNeXt |
| Attention type | Architecture | {ECA, SE, CBAM, None} | Channel/spatial emphasis vs. overhead |
| Normalization | Architecture | {BN, LN-like via GN(1), GN, EvoNorm, RMSNorm} | Stability across depths and batch regimes |
| Activation | Architecture | {SiLU (Swish), GELU, ReLU} | Smoothness and optimization behavior |
| Width multiplier | Architecture | [0.75, 1.0, 1.25] | Capacity scaling without redesign |
| Expand ratio | Architecture | [3, 4, 5] | Inverted bottleneck capacity |
| Final channels | Architecture | [1024, 1280, 1536] | Head representation richness |
| Conv bias usage | Architecture | {False, True} | Ablation of bias in conv layers |
| GN groups (LN-like) | Architecture | {1, 8, 16} | LayerNorm-like via GroupNorm; stability under small batches |
| Drop-connect rate | Regularization | [0.0, 0.3] (uniform) | Stochastic depth regularization |
| Hidden layers (head) | Classifier | {1, 2} | Separable vs. compact MLP head |
| Hidden size 1 | Classifier | {512, 1024} | Head capacity |
| Hidden size 2 | Classifier | {256, 512} | Secondary head capacity |
| Dropout (features) | Regularization | {0.1, 0.2} | Regularize pooled features |
| Dropout (head 1/2) | Regularization | {0.3, 0.5} | Regularize MLP head |
| Optimizer | Training | {AdamW, Adam, SGD, RMSProp} | Convergence vs. generalization |
| LR (head) | Training | [1e-4, 1e-3] (log-uniform) | Faster adaptation of new head |
| LR (backbone) | Training | [1e-5, 5e-4] (log-uniform) | Conservative backbone updates |
| Weight decay | Training | [1e-6, 5e-3] (log-uniform) | Regularization strength |
| Scheduler | Training | {OneCycle, Cosine, Step, Plateau} | Learning rate dynamics |
| Loss function | Objective | {Cross-Entropy, Focal, ASL, Dice} | Robustness to imbalance |
| Label smoothing | Objective | {0.0, 0.05} | Calibration |
| Focal α | Objective | {0.25, 0.5} | Class weighting in Focal loss |
| Focal γ | Objective | {1.0, 2.0, 3.0} | Hard example focusing |
| Mixup α | Augmentation | {0.0, 0.2} | Manifold mixup regularization |
| Seed | Reproducibility | {42} | Determinism where feasible |
The chosen configuration is trained from scratch on the full training set for a fixed number of epochs. Two learning rates are used: a relatively larger one for the classifier head and a smaller one for the backbone, encouraging rapid adaptation of the newly initialized head while maintaining stable feature learning in the backbone. Optimization uses AdamW, Adam, RMSProp, or SGD as determined by the search, paired with schedulers such as cosine annealing (with or without restarts), step, or plateau. The model is regularly evaluated on the validation set; training and validation curves are retained for analysis.
Let \(p\) denote the predicted class probability distribution and \(y\) the one-hot target.
The loss choice is dictated by the selected configuration; label smoothing may be used to improve calibration.
Performance is measured on a held-out test set using:
Where applicable, ROC-AUC is computed in a one-vs-rest manner. Macro-averaged metrics are emphasized due to potential class imbalance.
The selected configuration features a larger depthwise kernel, channel-focused attention, batch normalization, smooth activations, a moderate stochastic depth rate, and a two-layer classifier head with dropout operating on a high-dimensional pooled representation. This setup balances expressiveness and efficiency. After full training, the model typically yields strong macro-averaged performance on the test set. The following placeholder tables are provided to report final numbers.
| Split | Accuracy | Macro Precision | Macro Recall | Macro F1 |
|---|---|---|---|---|
| Validation | ||||
| Test |
| Metric | Train (Best) | Val (Best) |
|---|---|---|
| Loss | ||
| Accuracy | ||
| Macro F1 | — |
| Class | Precision | Recall | F1 | Support |
|---|---|---|---|---|
| Drawing | ||||
| Hentai | ||||
| Neutral | ||||
| Porn | ||||
| Sexy |
| Component | Key | Value (from selected run) |
|---|---|---|
| Architecture | Depthwise kernel | 7 |
| Architecture | Attention | ECA |
| Architecture | Normalization | BatchNorm |
| Architecture | Activation | GELU |
| Architecture | Width multiplier | 1.0 |
| Architecture | Expand ratio | 5 |
| Architecture | Final representation channels | 1536 |
| Architecture | Drop-connect rate | 0.1376 |
| Classifier | Hidden layers | 2 |
| Classifier | Hidden size 1 | 512 |
| Classifier | Hidden size 2 | 512 |
| Classifier | Dropout (features) | 0.1 |
| Classifier | Dropout (hidden) | 0.5 / 0.5 |
| Training | Batch size | 48 |
| Training | Image size | 224 |
| Optimization | Optimizer | RMSProp (example) |
| Optimization | LR (head) | 6.62e-4 |
| Optimization | LR (backbone) | 1.03e-4 |
| Optimization | Weight decay | 5.04e-6 |
| Scheduler | Type | Cosine (with restarts) |
| Objective | Loss | Cross-Entropy (ε=0.05) |
The exploration reveals that channel-focused attention (ECA) and GELU activations pair well with batch normalization for this task. A larger depthwise kernel and moderate drop-connect improve generalization on the nuanced NSFW categories. Split learning rates for head and backbone accelerate convergence without destabilizing feature learning. The system remains efficient, enabling practical deployment scenarios.